








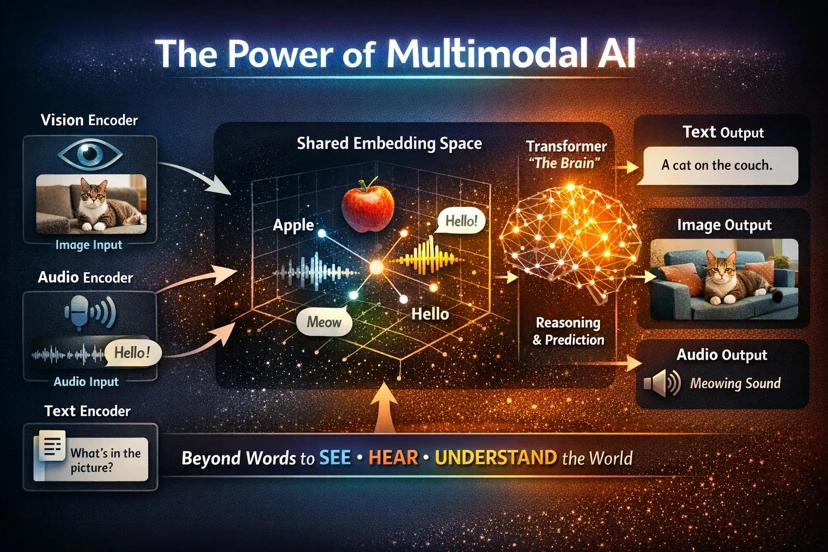
در مقاله قبلی بهصورت مفصل درباره مدلهای زبانی بزرگ یا همان LLM صحبت کردیم و دیدیم که چگونه این مدلها توانستهاند انقلابی در پردازش زبان طبیعی ایجاد کنند. از تولید متن گرفته تا پاسخگویی هوشمند، ترجمه، و حتی برنامهنویسی، همه و همه به کمک همین مدلها ممکن شدهاند. اما اگر کمی عمیقتر به دنیای واقعی نگاه کنیم، متوجه میشویم که اطلاعات فقط به متن محدود نمیشوند. بخش بسیار بزرگی از دادههایی که انسانها هر روز با آنها سروکار دارند، بهصورت تصویر، ویدیو و دادههای بصری هستند.
این مدلها با نام Vision Language Model یا به اختصار VLM شناخته میشوند.
در این مقاله قصد داریم پس از مروری بر LLM بهصورت کاملاً عمیق و مرحلهبهمرحله بررسی کنیم که دقیقاً VLM چیست و چگونه کار میکند، چه تفاوتهایی میان این دو وجود دارد و چرا بسیاری از شرکتهای پیشرو مانند پیشگامان لوتوس تمرکز خود را به سمت مدلهای چندوجهی یا Multimodal برده اند. اگر به آینده هوش مصنوعی علاقه مند هستی، این مقاله دقیقا همان چیزی است که باید بخوانی.
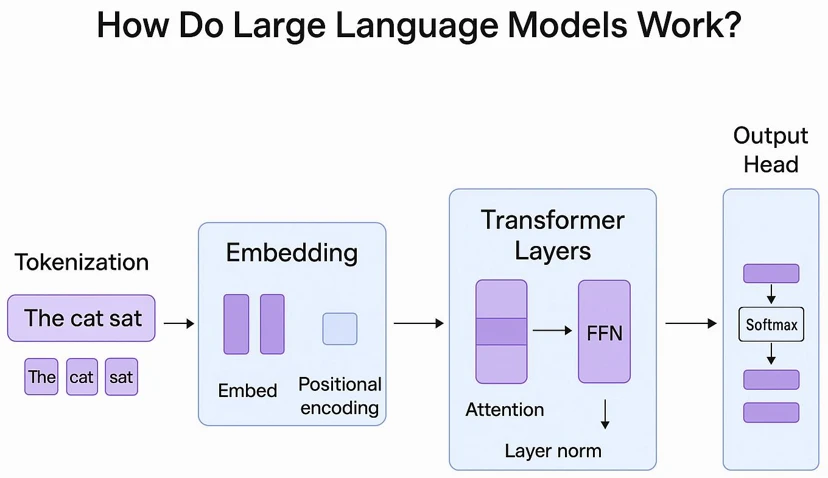
LLM چیست و چگونه کار میکند؟
همانطور که در مقاله قبل بررسی کردیم به صورت خلاصه:
مدلهای زبانی بزرگ در واقع سیستمهایی هستند که برای درک و تولید زبان انسان طراحی شدهاند. این مدلها بر پایه معماریهایی مانند Transformer ساخته میشوند و با استفاده از حجم عظیمی از دادههای متنی آموزش میبینند. در طول این فرآیند، مدل یاد میگیرد که چگونه کلمات به یکدیگر مرتبط هستند، ساختار جملات چگونه شکل میگیرد و معنا چگونه در زبان منتقل میشود.
زمانی که شما یک سوال از یک LLM میپرسید، این مدل در واقع با تحلیل الگوهای آماری موجود در دادههایی که قبلاً دیده است، بهترین پاسخ ممکن را تولید میکند. به همین دلیل است که خروجی آن اغلب بسیار طبیعی و شبیه به زبان انسان است.
در بسیاری از کاربردهای امروزی، از چتباتها گرفته تا سیستمهای تولید محتوا، LLMها نقش اصلی را ایفا میکنند. حتی در شرکتهایی مانند پیشگامان لوتوس، این مدلها بهعنوان هسته اصلی سیستمهای هوشمند پاسخگویی و تحلیل متن مورد استفاده قرار میگیرند.
با این حال، یک محدودیت مهم در LLMها وجود دارد و آن این است که این مدلها صرفاً با متن کار میکنند. یعنی اگر تصویری به آنها بدهید، در حالت عادی نمیتوانند آن را درک کنند. این دقیقاً همان نقطهای است که نیاز به نسل جدیدی از مدلها احساس میشود.
VLM چیست و چرا به وجود آمد؟
مدلهای VLM پاسخی به محددیتهای LLM هستند. این مدلها بهگونهای طراحی شدهاند که بتوانند همزمان دادههای متنی و تصویری را پردازش کنند. به بیان ساده، یک VLM میتواند یک تصویر را ببیند، محتوای آن را درک کند و سپس درباره آن به زبان انسان توضیح دهد یا به سوالات پاسخ دهد.
این توانایی باعث میشود که VLMها بسیار نزدیکتر به نحوه درک انسان از جهان عمل کنند. انسانها هنگام مشاهده یک صحنه، فقط تصویر را نمیبینند، بلکه آن را تفسیر میکنند، معنا میدهند و درباره آن صحبت میکنند.
VLMها دقیقاً تلاش میکنند همین فرآیند را شبیهسازی کنند.
برای مثال، اگر تصویری از یک خیابان شلوغ به یک VLM بدهید و از آن بپرسید چه چیزی در تصویر دیده میشود، مدل میتواند خودروها، افراد، تابلوها و حتی شرایط محیطی را تشخیص دهد و یک توضیح کامل ارائه دهد.
در حوزههای صنعتی، این قابلیت اهمیت بسیار زیادی دارد. شرکتهایی مانند پیشگامان لوتوس از VLMها برای تحلیل تصاویر پزشکی، بررسی دادههای بصری در صنعت و حتی بهبود سیستمهای نظارتی استفاده میکنند.

تفاوت LLM و VLM به زبان ساده اما عمیق
اگر بخواهیم تفاوت این دو نوع مدل را بهصورت مفهومی توضیح دهیم، باید بگوییم که LLMها متخصص زبان هستند، در حالیکه VLMها متخصص درک چندرسانه ای هستند.
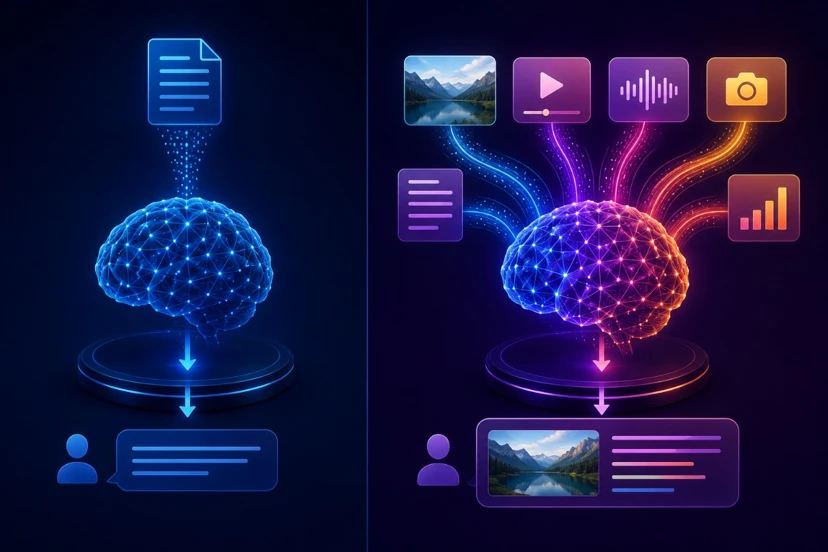
یک LLM تنها با متن سروکار دارد؛ ورودی آن متن است و خروجی آن نیز متن خواهد بود. این مدلها در درک ساختار زبان، تولید محتوا و پاسخگویی بسیار قدرتمند هستند، اما دنیای آنها محدود به کلمات است.
در مقابل، VLMها دنیای گستردهتری دارند. آنها میتوانند تصویر را بهعنوان ورودی دریافت کنند، آن را تحلیل کنند و سپس خروجی متنی تولید کنند. به همین دلیل، این مدلها قادرند درباره چیزهایی صحبت کنند که صرفاً در متن وجود ندارند، بلکه در دنیای واقعی دیده میشوند.
از نظر پیچیدگی نیز VLMها معمولاً پیچیدهتر هستند، زیرا باید دو نوع داده کاملاً متفاوت را بهصورت همزمان پردازش کنند و بین آنها ارتباط برقرار کنند. این یعنی آنها نهتنها باید زبان را بفهمند، بلکه باید مفاهیم بصری را نیز درک کنند و این دو را به یکدیگر متصل کنند.
چرا VLMها آینده هوش مصنوعی هستند؟
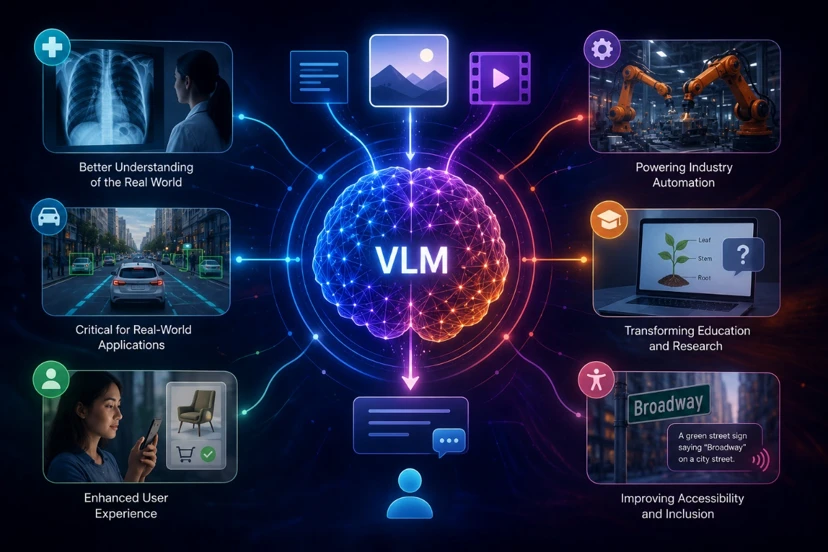
دلیل اصلی اهمیت VLMها این است که جهان واقعی چندوجهی است. ما در زندگی روزمره فقط با متن سروکار نداریم، بلکه تصاویر، ویدیوها، نمودارها و حتی محیطهای فیزیکی نقش بسیار مهمی در انتقال اطلاعات دارند.
VLMها این امکان را فراهم میکنند که هوش مصنوعی بتواند این دنیای پیچیده را بهتر درک کند. به همین دلیل، کاربردهای آنها بسیار گسترده تر از LLMهاست.
در حوزه پزشکی، این مدلها میتوانند تصاویر رادیولوژی را تحلیل کنند و به پزشکان در تشخیص کمک کنند. در صنعت خودرو، میتوانند به خودروهای خودران کمک کنند تا محیط اطراف خود را بهتر بشناسند. در حوزه امنیت، میتوانند برای تشخیص چهره یا تحلیل رفتار استفاده شوند.
شرکتهایی مانند پیشگامان لوتوس با درک این روند، سرمایهگذاری قابلتوجهی روی توسعه این مدلها انجام دادهاند، زیرا بهخوبی میدانند که آینده هوش مصنوعی در گرو توانایی درک همزمان متن و تصویر است.
آیا VLM جایگزین LLM خواهد شد؟
پاسخ کوتاه این است که نه، اما پاسخ کاملتر کمی پیچیدهتر است.
LLMها همچنان بهترین گزینه برای پردازش خالص متن هستند و در بسیاری از کاربردها، استفاده از آنها منطقیتر و بهینهتر است. اما VLMها درواقع یک گام جلوتر هستند و میتوانند در سناریوهایی استفاده شوند که نیاز به درک تصویر نیز وجود دارد.
در واقع، بهجای اینکه این دو را رقیب یکدیگر بدانیم، بهتر است آنها را مکمل هم در نظر بگیریم. بسیاری از سیستمهای پیشرفته امروزی، ترکیبی از این دو نوع مدل را استفاده میکنند تا بتوانند بهترین عملکرد را ارائه دهند. این همان مسیری است که شرکتهایی مانند پیشگامان لوتوس نیز در پیش گرفتهاند.
جمعبندی نهایی
اگر بخواهیم تمام مطالب این مقاله را در یک نگاه جمعبندی کنیم، باید بگوییم که LLMها نقطه شروع تحول در هوش مصنوعی مدرن بودند. آنها نشان دادند که ماشینها میتوانند زبان انسان را درک کنند و با ما ارتباط برقرار کنند. اما این تنها آغاز راه بود.
VLMها این مسیر را یک قدم جلوتر بردهاند و به هوش مصنوعی این توانایی را دادهاند که نهتنها زبان، بلکه جهان اطراف را نیز درک کند. این یعنی حرکت از یک هوش مصنوعی متنی به سمت یک هوش مصنوعی چندوجهی که میتواند مانند انسان، هم ببیند و هم بفهمد.
در آیندهای نهچندان دور، مرز بین این مدلها کمرنگتر خواهد شد و ما شاهد سیستمهایی خواهیم بود که بهصورت یکپارچه متن، تصویر، صدا و حتی ویدیو را پردازش میکنند. این همان آیندهای است که بسیاری از شرکتهای پیشرو مانند پیشگامان لوتوس در حال ساخت آن هستند.
اگر امروز بخواهی وارد این حوزه شوی، بهترین مسیر این است که ابتدا درک عمیقی از LLMها پیدا کنی، سپس به سراغ VLMها بروی و در نهایت روی مدلهای چندوجهی تمرکز کنی.. این مسیر نهتنها تو را با فناوریهای روز آشنا میکند، بلکه تو را برای آیندهای آماده میکند که در آن هوش مصنوعی نقش بسیار پررنگتری در زندگی انسانها خواهد داشت.
حرف آخر
دنیای هوش مصنوعی بهسرعت در حال تغییر است و مفاهیمی که امروز جدید به نظر میرسند، فردا به استاندارد تبدیل خواهند شد. در این میان، درک تفاوت بین LLM و VLM میتواند یک مزیت رقابتی مهم برای هر فرد یا کسب و کاری باشد.
پیشگامان لوتوس و سایر شرکتهای پیشرو بهخوبی این موضوع را درک کردهاند و در حال حرکت به سمت آیندهای هستند که در آن هوش مصنوعی نهتنها مینویسد، بلکه میبیند، تحلیل میکند و تصمیم میگیرد.
مقاله های ما:"LLM چیست و چگونه کار میکند؟ | راهنمای کامل از صفر تا صد"