What is a VLM and How is it Different from an LLM? A Complete Guide from Fundamentals to Advanced Concepts
What is a VLM and How is it Different from an LLM?

In our previous blog, we explored Large Language Models (LLMs) in depth and saw how they revolutionized natural language processing. From generating human-like text to answering complex questions, translating languages, and even writing code, LLMs have become the backbone of modern AI systems.
However, if we take a step back and look at the real world, we quickly realize that information is not limited to text. A significant portion of human knowledge comes in the form of images, videos, and other visual data.
This is where a new generation of AI models comes into play—models that not only read but also see and understand. These are called Vision-Language Models, or VLMs.
In this article, after a brief review of LLMs, we aim to explore in depth and step by step what VLMs exactly are, how they work, and what role they will play in the future of artificial intelligence., the fundamental differences between them, and why forward-thinking companies like Pishgaman Lotus are shifting their focus toward multimodal AI systems. If you're interested in the future of artificial intelligence, this guide is essential reading.
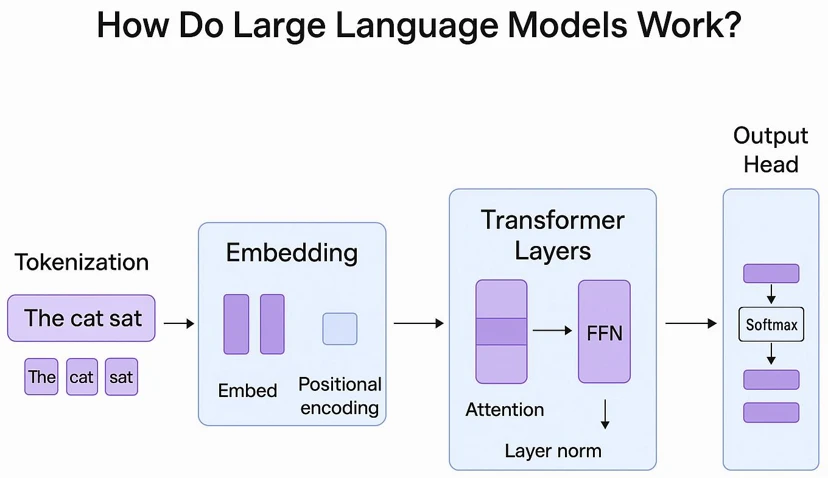
What is an LLM and How Does It Work?
Large Language Models (LLMs) are AI systems designed to understand and generate human language. These models are typically built on architectures such as Transformers and are trained on massive datasets of text.
During training, the model learns patterns in language, including grammar, context, relationships between words, and semantic meaning. When you ask a question, the LLM analyzes these learned patterns and generates the most probable and contextually appropriate response.
This is why LLM outputs often feel natural and human-like.
Today, LLMs are widely used in applications such as chatbots, content generation tools, translation systems, and coding assistants. Companies like Pishgaman Lotus leverage LLMs to build intelligent response systems and advanced text-processing solutions.
However, LLMs have a key limitation: they operate purely on text. They cannot inherently understand images or visual data. This limitation paved the way for more advanced models.
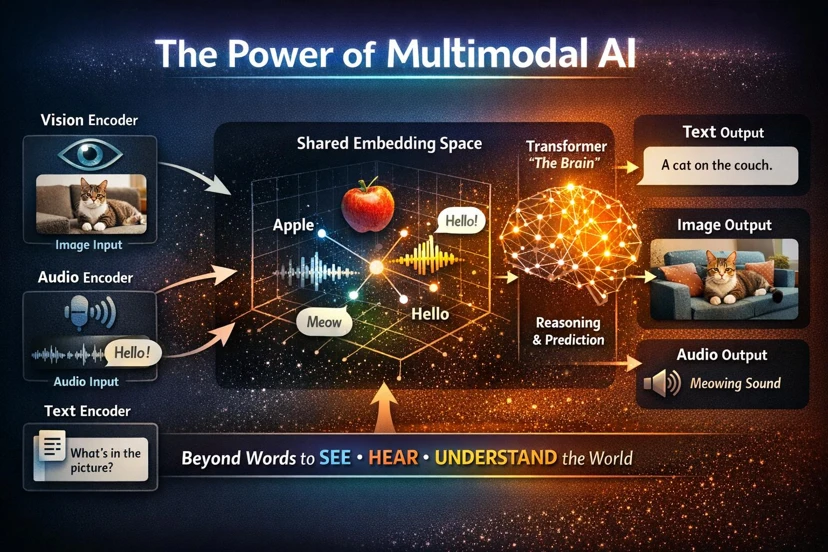
What is a VLM and Why Was It Created?
Vision-Language Models (VLMs) are designed to overcome the limitations of LLMs by combining visual understanding with language processing.
In simple terms, a VLM can analyze an image, understand its content, and then describe it or answer questions about it using natural language.
This makes VLMs much closer to how humans perceive the world. Humans don’t just read text—we interpret visual scenes, connect them with context, and describe them using language. VLMs attempt to replicate this ability.
For example, if you provide an image of a busy street and ask what is happening, a VLM can identify cars, people, traffic signs, and environmental conditions, then generate a meaningful description.
In industrial applications, this capability is extremely valuable. Companies such as Pishgaman Lotus are using VLMs in areas like medical image analysis, industrial inspection, and intelligent surveillance systems.

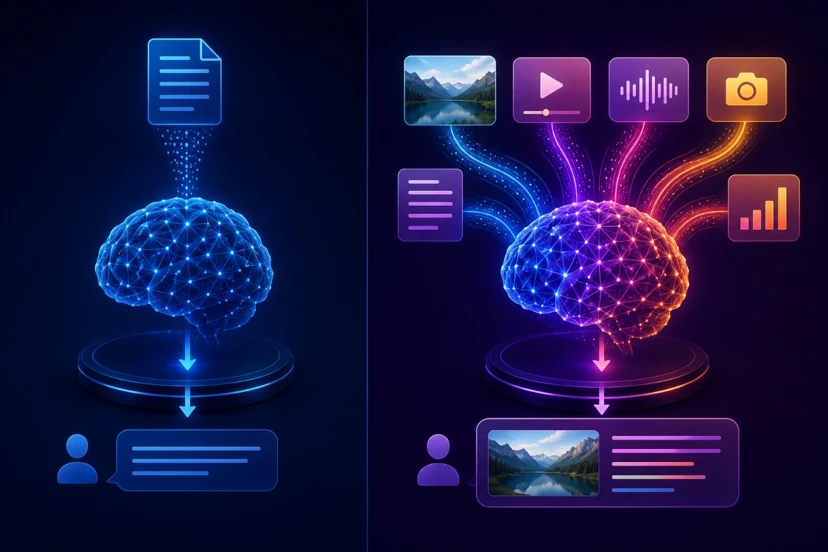
The Difference Between LLM and VLM (Conceptual View)
At a fundamental level, LLMs are language specialists, while VLMs are multimodal intelligence systems.
An LLM processes text as both input and output. It excels at understanding linguistic patterns, generating content, and handling purely textual tasks. However, its understanding is limited to what can be expressed in words.
A VLM, on the other hand, operates across multiple data types. It can take both images and text as input, interpret visual information, and produce text as output. This allows it to describe real-world scenes and reason about visual content.
In terms of complexity, VLMs are generally more advanced because they must bridge two fundamentally different domains: vision and language. They need to understand visual features and map them into meaningful linguistic representations.
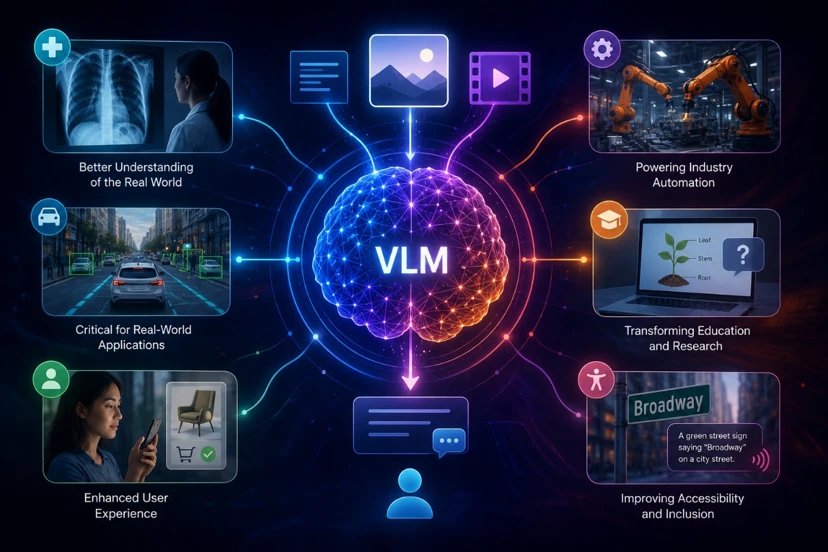
Why Are VLMs the Future of AI?
The primary reason VLMs are gaining importance is that the real world is inherently multimodal. Humans interact with text, images, videos, and physical environments simultaneously.
VLMs enable AI systems to better understand this complexity. As a result, their applications are significantly broader.
In healthcare, VLMs can analyze radiology images and assist doctors in diagnosis. In autonomous driving, they help vehicles understand their surroundings. In security systems, they enable facial recognition and behavior analysis.
Forward-looking companies like Pishgaman Lotus are investing heavily in this field because they recognize that the future of AI lies in combining multiple modalities into a single intelligent system.
Will VLM Replace LLM?
The short answer is no—but the full answer is more nuanced.
LLMs remain the best choice for purely text-based tasks and are highly efficient in those domains. However, VLMs extend these capabilities by adding visual understanding.
Rather than replacing LLMs, VLMs complement them. Many advanced AI systems today combine both approaches to achieve better performance and broader functionality.
This hybrid approach is also being adopted by companies like Pishgaman Lotus, which integrate both language and vision capabilities into their AI solutions.
Final Conclusion
If we look at the bigger picture, LLMs marked the beginning of the modern AI revolution by enabling machines to understand and generate human language.
VLMs take this one step further by allowing AI to understand not just language, but the world itself. This represents a shift from text-based intelligence to fully multimodal intelligence.
In the near future, the boundaries between these models will blur, leading to unified systems capable of processing text, images, audio, and video seamlessly.
This is the future that leading companies like Pishgaman Lotus are actively building.
If you want to enter this field, the best path is to first master LLMs, then move on to VLMs, and finally focus on multimodal AI systems. This journey will prepare you for a future where artificial intelligence plays an even more central role in our lives.
Final Thoughts
Artificial intelligence is evolving rapidly. Concepts that seem cutting-edge today will become standard tomorrow.
Understanding the difference between LLMs and VLMs gives you a strong advantage, whether you are a developer, entrepreneur, or tech enthusiast.
Companies like Pishgaman Lotus are already embracing this transformation and moving toward a future where AI not only writes but also sees, analyzes, and makes intelligent decisions.

Have special project to begin?
Contact us if you need a unique website for your special requirements, if you think having a mobile application help you reach your business’s goals or you still do not recognize which product can help you implement your ideas. Lotus Pioneers accompany you to develop your business through consulting and by designing special products.